last change: 13 Oct. 2006
Overview
This page describes results of mysql supersmack tests on 8 core opteron server.
This is an sequel to the tests done in May 2006 in response to call for testing
of Unix Domain Socket locking patch by Robert Watson.
Back in May the results indicated that we get large increase in performance
for smaller thread counts (<20) and will take serious hit with 30+ threads.
The summary of the tests done in September 2006 is basically that whatever it
was that caused this effect is now gone and we get stable ~50% performance increase
with all the tested threadcounts.
On the other hand performance seems to be maxed out at 4 cores, after that it will
get couple of % worse with every added core. I'm not sure why exactly... Originally I
thought it was because of high lock contention around filedesc lock,
but eliminating them from the most highly contended paths only gave ~2-3% performance boost.
The top most contended mutexes left after all the hacks I used are following
With the normal profiling code (selectsmack 100 10000) [full]:
max total count avg cnt_hold cnt_lock name
26 16957 2743 6 793 607 /usr/src/sys/amd64/amd64/pmap.c:2248 (vm page queue mutex)
9 225 41 5 2 1154 /usr/src/sys/kern/sys_pipe.c:589 (pipe mutex)
278 1843008 203474 9 21 1901 /usr/src/sys/kern/kern_synch.c:220 (process lock)
2453 1875960 203011 9 6067 5860 /usr/src/sys/kern/sys_generic.c:1147 (sellck)
155 5404177 203299 26 75091 48649 /usr/src/sys/kern/subr_sleepqueue.c:374 (process lock)
2550 7046590 800643 8 213926 205968 /usr/src/sys/kern/kern_sig.c:998 (process lock)
With some mutex profiling patches from Kris Kennaways p4 contention branch (selectsmack 100 10000)[full]:
count cnt_hold cnt_lock name
36000820 10958 7707 /usr/src/sys/kern/uipc_usrreq.c:730 ((null))
4000443 4335 10420 /usr/src/sys/kern/uipc_socket.c:1253 ((null))
283713 3194 16357 /usr/src/sys/kern/kern_synch.c:220 ((null))
2012420 7610 16809 /usr/src/sys/kern/sys_generic.c:1147 ((null))
7015477 14062 67866 /usr/src/sys/kern/kern_descrip.c:439 ((null))
1250354 63441 73270 /usr/src/sys/kern/kern_umtx.c:318 ((null))
2300682 267327 145152 /usr/src/sys/kern/subr_sleepqueue.c:374 ((null))
6032488 189853 499840 /usr/src/sys/kern/kern_sig.c:998 ((null))
50616757 618120 656922 /usr/src/sys/kern/kern_descrip.c:2164 ((null)) [this is FILE_LOCK in fdrop()]
What really surprises me here is why doesn't the FILE lock contention show up at all with the standard profiling code.
spinlock profile for select 100 10000: debug.spinlock.prof.count: 51515252
Kernel profiling shows that awfully lot of time is spent in mutex spin (select 10 10000) [full]:
% cumulative self self total
time seconds seconds calls ms/call ms/call name
63.4 14393.00 14393.00 0 100.00% _mtx_lock_spin [1]
19.4 18790.00 4397.00 0 100.00% _mtx_lock_sleep [2]
2.9 19439.00 649.00 0 100.00% DELAY [3]
1.5 19784.00 345.00 0 100.00% soreceive_generic [4]
1.2 20059.00 275.00 0 100.00% Xfast_syscall [5]
mutex profiles for some of the configurations and the exact resultsets can be found here.
Environment:
Hardware:
- motherboard: Thunder K8QSD Pro
- hdd: scsi seagate cheetah 10K7
- ram: 8 * 3200 CL3 kingston ECC 1G
- cpu: 4 * opteron 870 (2Ghz dualcore)
mysql:
- ver: 4.1.21 from the ports
- table type: MyISAM
- config: my-huge.cnf with disabled bin-log and max-connections bumped to 400
freebsd:
libthr was used in all cases
6.2 prerelease was used without any changes (default SMP kernel config)
on freebsd current malloc debug was turned off and debug options were taken out of GENERIC, otherwise the config was default
Machine has different storage subsystem config than the one in original tests (raid0 vs. raid5),
so the update results are not directly comparable with May results, everything else should be identical.
Legend
6.2_pre - freebsd 6.2 prerelease
fbsd_current - freebsd current cvsuped @ 25 Sep 2006
fbsd_current_udsp - previous + patch from Robert Watson for splitting up UNP lock around unix domain socket
freebsd_p2 - previous + patch for avoiding GIANT for some fileops + patch to ignore uid socket buffer size information limits&changes when rlimit is not set
freebsd_p3 - previous + patch to use shared locks around filedesc struct
Select smack
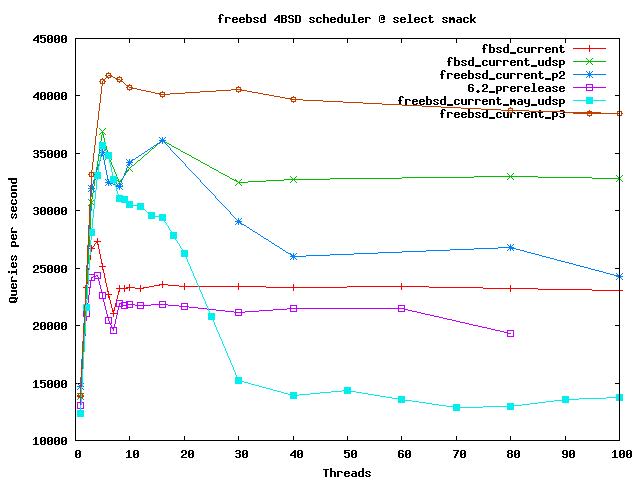
6.2 pre results fluxuated a lot with 80+ threads, so results for those threadcounts were ignored.
freebsd_p2 also had very large fluxuations with 80+ threads.
interesting thing to notice here is that freebsd_current_p2 once again shows behaviour somewhat similar to May results, where getting rid of highly contended locks actually pessimizes the performance. For some unknown reason it does not do that with ULE scheduler as we can see on the next graph.
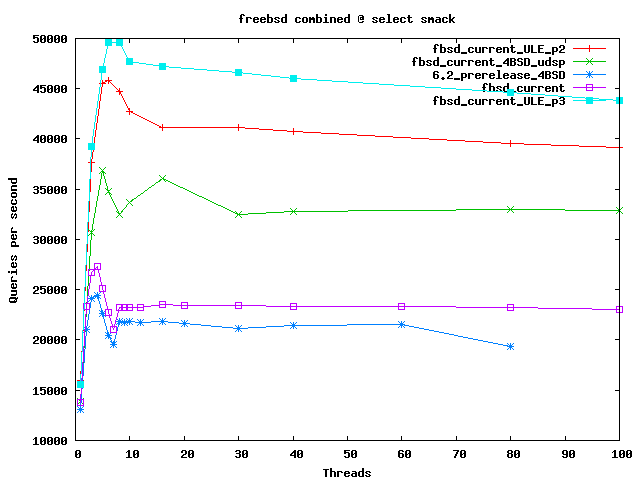
This graph shows some of the more experimental stuff like using alternative schedulers and rather experimental patches.
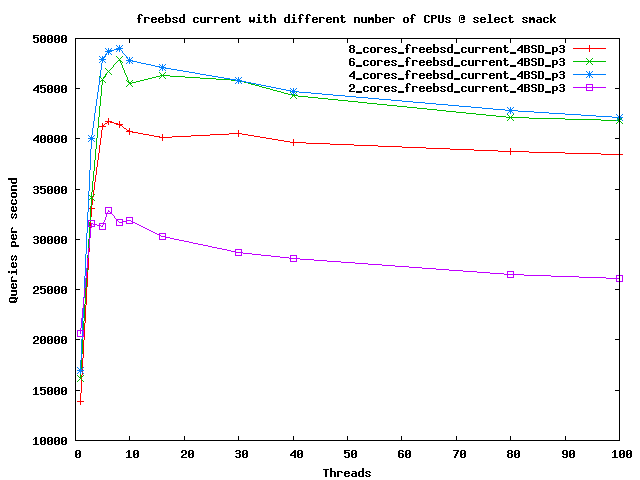
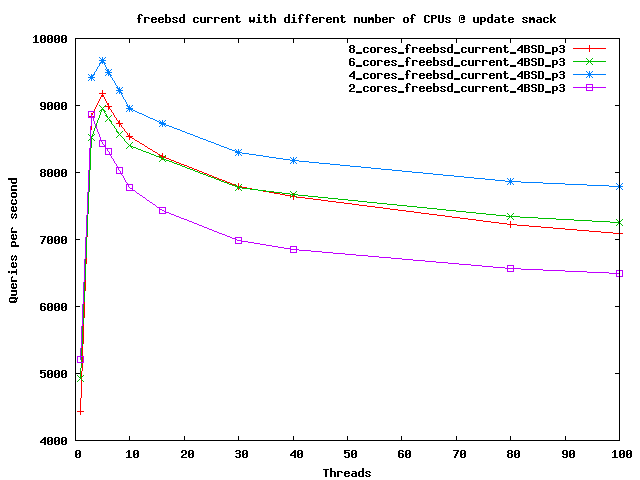
Here's a graph showing that we actually get better performance when we remove some cpus. This is caused by smaller
lock contention. Mutex profiles still show a lot of it, so the results can probably get much better.
4 cores seems to be most optimal configuration at the moment.
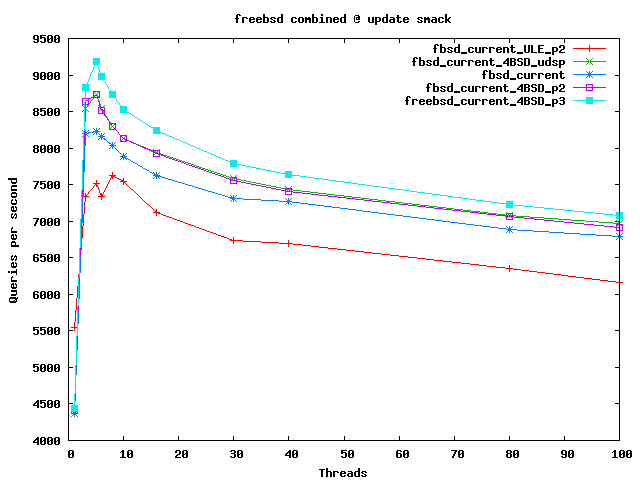
Update smack